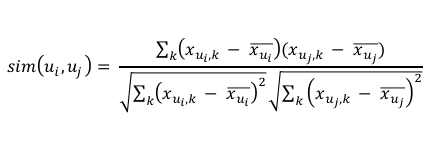【推荐系统】相似度量
在推荐系统以及其他相关行业中经常会用到相似度量,基于相似user或者item做推断、统计
在判定相似时,存在一些常用的相似计算的方式:欧氏距离、余弦距离、皮尔逊相似度等
那如何判断应该使用那种距离计算方式去计算相似度呢
- 欧氏距离评估的是位置差异,实质就是喜好均值差异
- 余弦距离评估的是方向差异,实质就是兴趣差异
- 皮尔逊相似度主要针对的是购物篮数据,来评估选择的交集情况
举个俗套的电影评分的例子:
如果没有具体的分值度量,用户只标记其喜欢的电影(或者认为看过即喜欢,而没有喜好程度),我们可以认为如果两个用户看的电影基本一直,则这两个用户看电影的品味就很相似,这个时候往往使用皮尔逊度量是相对合适的
而当用户标记的电影存在的喜欢的程度,就有了位置差异的概念了。比如对比《肖生克的救赎》和《忠犬巴公》,我和你可能都更喜欢《忠犬巴公》多一点,而另外一个小伙伴更喜欢《肖生克的救赎》,但是我打分水平和另外小伙伴的打分水平都相对高一点在8+,而你对电影可能要求更严格一些,评分多集中在6左右
那从兴趣点差异来讲,我和你的观影审美是比较一致的,而另外的小伙伴就和我们有差异,这时候就可以用余弦距离了,余弦距离和皮尔逊度量的差异就在于有了喜好程度的不同
但是从喜好均值来讲,我和另一个小伙伴的打分均值更接近,而和你相差更远一点,这时就需要用欧式距离来计算了
而在推荐系统里面,大部分时候我们都建立在一个假设:基于兴趣相似做推荐,也就是观影时,你个人对哪部电影更感兴趣,所以往往选择预先距离进行计算,但是不同应用场景这个假设可能会发生变化,如在做购物意愿的判断时,做推荐的需求就是像那些有购物倾向的人做推荐,而不单单考虑兴趣了(因为关注营收的人并不care那些对商品很有兴趣但是无论如何也不会买的人)
更深一步讲,这其实就涉及到用户在整个行为链过程中,不同环节的关注点和计算逻辑是不同的,评判相似的依据也是不同的。所以建模和实际需求的关联很重要。。。
补充一个同时考虑位置和方向的相似评估方法:
可按照自己的需求构建相应的相似评估方式~~